公司前段时间采购了《重构:改善既有代码的设计(第2版)》 这本书,最近刚好有时间阅读了下。强烈推荐给大家阅读。现在分享下自己的感受。
# 重构的原则
不知道大家有没有发现,现在的公司特别的互联网公司经常会提到重构。 往前倒退几年反而都没怎么听到过,为什么? 以前软件公司都是传统行业居多,软件架构也采用的瀑布模型各个极端拆分的很具体,只要需求文档,设计文档设计好以后就不会改变。这个时候不管把代码写成什么样,只要有设计文档都可以快速定位问题;现在软件公司都是互联网行业居多,特征就是快,拥抱变化,最短时间创建最大收益。对软件的可维护性要求很高:需要加新的功能、需要修改旧的功能。这样随之而来的是大量人工的投入、运维成本的加大等。所以现在大家都在提倡重构,好大代码是让人看懂,不是让机器看懂。
# 何为重构
重构(名词):对软件内部结构的一种调整,目的是在不改变软件可观察行为的前提下,提高其可理解性,降低其修改成本。
重构(动词):使用一系列重构手法,在不改变软件可观察行为的前提下,调整其结构。
# 为何重构
- 重构改进软件设计
- 重构是软件更容易理解
- 重构帮助找到bug
- 重构提高编程速度
# 何时重构
- 添加新功能时
重构的最佳时机就是在添加新功能之前
- Code Review时
review 审查代码并提出建议
- 理解代码时
在理解代码在做什么的时候,发现就可以重构
- 定期重构、长期重构
# 何时不重构
- 不知道凌乱代码的逻辑时
- 重写比重构还容易的时候
# 坏代码的味道
这里就列举了9个平常容易看到的例子
- 神秘命名(Mysterious Name)
如果你想不出一个好名字,说明背后很可能潜藏着更深的设计问题。为一个恼人的名字所付出的纠结,常常能推动我们对代码进行精简。
- 重复的代码(Duplicated Code)
看到相同的代码结构,那么可以合并。
- 过长函数(Long Function)
函数越长,就越难理解。每当感觉需要以注释来说明点什么的时候,我们就把需要说明的东西写进一个独立函数中。
- 过长参数列表(Long Parameter List)
使用类可以有效地缩短参数列表。
- 全局数据(Global Data)
全局数据的问题在于,从代码库的任何一个角落都可以修改它,而且没有任何机制可以探测出到底哪段代码做出了修改。
- 依恋情结(Feature Envy)
一个函数跟另一个模块中的函数或者数据交流格外频繁就把它们放在一起。原则是:判断哪个模块拥有的此函数使用的数据最多,然后就把这个函数和那些数据摆在一起。
- 数据泥团(Data Clumps)
两个类中相同的字段、许多函数签名中相同的参数。这些总是绑在一起出现的数据真应该拥有属于它们自己的对象。
- 过大的类(Large Class)
类内如果有太多代码,可以拆分多个函数。
- 注释(Comments)
当你感觉需要撰写注释时,请先尝试重构,试着让所有注释都变得多余。
# 测试
在做重构的时候已经要先补全功能的单元测试,这样才能保证原功能与重构后的功能一样
# 自测的价值
- 一套测试就是一个强大的bug侦测器,能够大大缩减查找bug所需的时间。
- 每当你收到bug报告,请先写一个单元测试来暴露这个bug。
- 测试远不止如此
# 重构方法
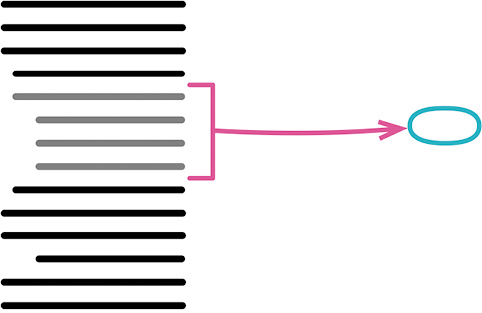
# 提炼函数(Extract Function)
function printOwing(invoice) {
printBanner();
let outstanding = calculateOutstanding();
//print details
console.log(`name: ${invoice.customer}`);
console.log(`amount: ${outstanding}`);
}
2
3
4
5
6
7
8
function printOwing(invoice) {
printBanner();
let outstanding = calculateOutstanding();
printDetails(outstanding);
function printDetails(outstanding) {
console.log(`name: ${invoice.customer}`);
console.log(`amount: ${outstanding}`);
}
}
2
3
4
5
6
7
8
9
10
做法
- 创造一个新函数,以它“做什么”来命名;
- 将待提炼的代码从源函数复制到新建的目标函数中;
- 仔细检查提炼出的代码引用是否没问题;
- 都处理完之后,编译;
- 将被提炼代码段替换为对目标函数的调用;
- 测试
有时提炼一个函数,尝试使用它,然后发现不太合适,再把它内联回去,这完全没问题。只要在这个过程中学到了东西。
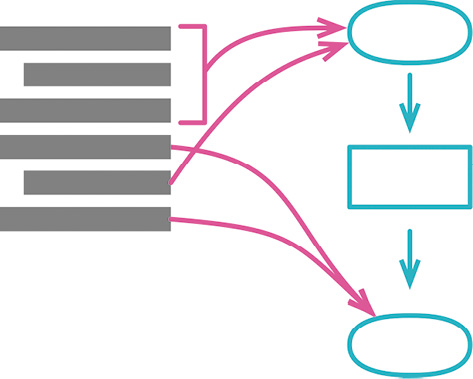
# 拆分阶段(Split Phase)
const orderData = orderString.split(/\s+/);
const productPrice = priceList[orderData[0].split("-")[1]];
const orderPrice = parseInt(orderData[1]) * productPrice;
2
3
const orderRecord = parseOrder(order);
const orderPrice = price(orderRecord, priceList);
function parseOrder(aString) {
const values = aString.split(/\s+/);
return ({
productID: values[0].split("-")[1],
quantity: parseInt(values[1]),
});
}
function price(order, priceList) {
return order.quantity * priceList[order.productID];
}
2
3
4
5
6
7
8
9
10
11
12
13
做法
- 代码提炼成独立的函数;
- 测试;
- 引入一个到数据结构中,将其作为参数添加到提炼出的新函数的参数列表中;
- 测试;
- 引入第二个到数据结构中;
- 测试
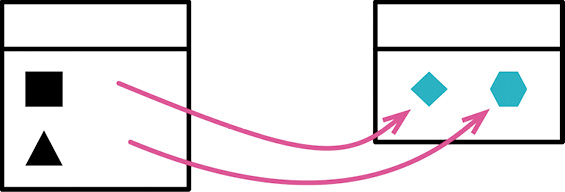
# 提炼类(Extract Class)
class Person {
get officeAreaCode() {return this._officeAreaCode;}
get officeNumber() {return this._officeNumber;}
2
3
class Person {
get officeAreaCode() {return this._telephoneNumber.areaCode;}
get officeNumber() {return this._telephoneNumber.number;}
}
class TelephoneNumber {
get areaCode() {return this._areaCode;}
get number() {return this._number;}
}
2
3
4
5
6
7
8
做法
- 决定如何分解类所负的责任;
- 创建一个新的类,用以表现从旧类中分离出来的责任;
- 测试;
一个类应该是一个清晰的抽象,只处理一些明确的责任,等等。但是在实际工作中,类会不断成长扩展。你会在这儿加入一些功能,在那儿加入一些数据。给某个类添加一项新责任时,你会觉得不值得为这项责任分离出一个独立的类。于是,随着责任不断增加,这个类会变得过分复杂。很快,你的类就会变成一团乱麻。
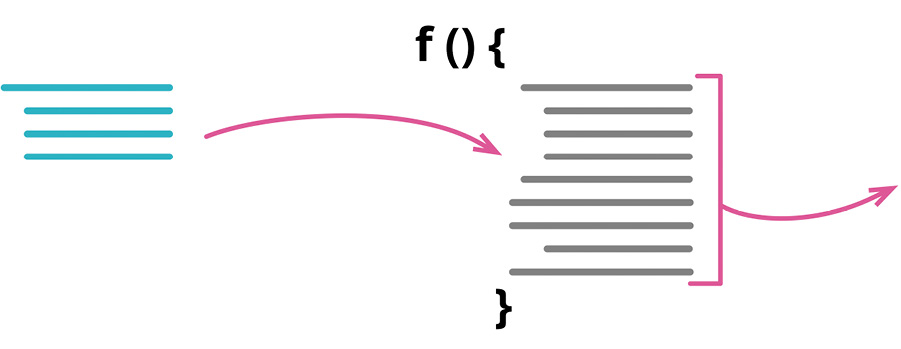
# 替换算法(Substitute Algorithm)
function foundPerson(people) {
for(let i = 0; i < people.length; i++) {
if (people[i] === "Don") {
return "Don";
}
if (people[i] === "John") {
return "John";
}
if (people[i] === "Kent") {
return "Kent";
}
}
return "";
}
2
3
4
5
6
7
8
9
10
11
12
13
14
function foundPerson(people) {
const candidates = ["Don", "John", "Kent"];
return people.find(p => candidates.includes(p)) || '';
}
2
3
4
做法
- 整理一下待替换的算法,保证它已经被抽取到一个独立的函数中;
- 先测试原函数,以便固定它的行为;
- 再替换为新函数;
- 执行静态检查;
- 运行测试,比对新旧算法的运行结果;